Уроки разработки полетного софта
Feb 17, 2018 · CommentsNASAКосмосПрограммирование
Часто, когда речь заходит про космический софт, можно слышать “ну уж там-то код компилируется со всеми предупреждениями”, или “ну уж там-то наверняка запускается статический анализатор кода и все ошибки исправляются”, или “ну уж там то тесты покрывают код на 100%”. Как вы скорее всего уже догадались рая нет. Вернее, рай в планах был, но из-за превышения сметы успели достроить только ад. К счастью, костры успели развести только под половиной котлов, поскольку часть дров заменили бетонными шпалами, а расположение котлов забыли задокументировать.
Сайт NASA Lessons Learned полон таких историй. Сегодня мы пройдемся по результатам исследования Flight Software Engineering Lessons за авторством Ronald Kirk Kandt опубликованное на конференции AMCIS 2009 (Americas Conference on Information Systems). Автор исследования просуммировал результаты других работ, посвященных трудностям процесса разработки программного обеспечения, а также результаты расследования аварий реальных космических аппаратов.
Начнем с того, что стоимость разработки софта превышает начальную смету на 50% в среднем. Этим, понятное дело, никого не удивишь. Гораздо интереснее знать почему это происходит. Итак:
- Срок выпуска софта определяется окнами запуска, которые очень сложно изменить. Иногда возможно переключится на другую траекторию полета. Иногда ждать следующей возможности приходится ждать годами.
- Софт и железо разрабатывается одновременно, что было бы очень здорово, если
бы не несколько проблем:
- Требования к софту постоянно меняются в процессе разработки. Многие требования фиксируются в последний момент. Изменения требований часто вызывает каскадную волну изменений сразу во многих подсистемах.
- Взаимодействие разработчиков софта и железа в части формулирования требований часто оставляет желать лучшего.
- Готовность тестового оборудования постоянно ползет вправо (естественно, оно же еще в разработке).
- Повторное использование кода случается гораздо реже, чем принято думать (повторное использование кода без изменений - это скорее исключение из правил; внесение изменений запускает цикл “анализ требований” - “новый дизайн” - “новый код”).
От себя добавлю, что связность разных компонент космического аппарата очень высока. Изменения в одном компоненте часто влекут изменения во многих других компонентах. Причина тут в том, что космический аппарат - это сильно оптимизированная система. Например, если есть на аппарате определенный датчик, то им будут пользоваться все, даже если разным разным компонентам было бы удобнее пользоваться разными датчиками (так как им нужны слегка разные данные) - масса аппарата гораздо более важный параметр.
Далее идет разбор конкретных аварий. Первопричина потери Mars Climate Orbiter заключалась в использовании неправильных единиц измерения. Наземный софт, разработанный в Lockheed Martin, генерировал файл в который среди прочего сохранялся полный импульс в фунтах в секунду. Другая наземная система, разработанная NASA, использовала этот файл предполагая, что полный импульс записан в ньютонах в секунду. В результате аппарат приблизился к Марсу на 57 км
- ниже минимальной высоты в 80 км, которую он мог выдержать.
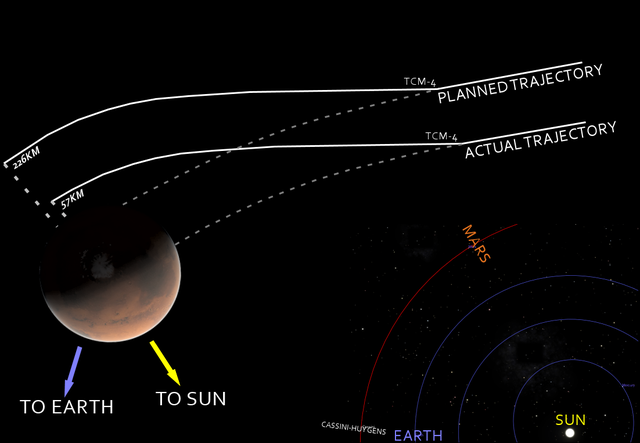
Несоответствие не было выявлено ранее по целому комплексу причин:
- Изначально, файл генерировался с ошибками и операторы использовали другой способ получения нужных данных.
- Наземное программное обеспечение не было адекватно протестировано, в том числе не было проведено интерграционное тестирование (вспоминаем второй запуск с Восточного).
- Коммуникационные проблемы:
- Операторы навигации не участвовали в обзорах и одобрении проектного дизайна (preliminary & critical design review).
- Несоответствие между измеренными и вычисленными параметрами были замечены как минимум двумя операторами, но их озабоченность была в конечном итоге проигнорирована.
- Один из маневров коррекции был запланирован, но так и не проведен.
Mars Polar Lander был потерян во время посадки в 1999 году. Точная причина аварии не была установлена из-за отсутствии телеметрии. Расследование показало, что наиболее вероятная причина аварии заключалась в досрочном выключении посадочных двигателей из-за неадекватной реакции полетного ПО на временный сигнал в измерениях датчиков.
Опять же, первопричина аварии нашлась не в софте:
- Запуск Mars Polar Lander проходил в условиях беспрецедентных технических и финансовых ограничений, многие из которых были явно нереалистичными.
- Из-за финансовых ограничений, моделирование и анализ использовались для замены инспекций и тестирования. Недочеты выявленные в процессе одобрения проектного дизайна не были устранены.
- Программное обеспечение не было достаточно протестировано. Софт не тестировался в полетной конфигурации.
Как видите, разработка космического софта подвержена тем же проблемам, что и разработка обычного. Сроки поджимают, людей не хватает, железо не готово. В таких условиях требовать 100% покрытия кода тестами, полное отсутствие предупреждений компилятора, полную формальную верификацию софта и прочих приятных в теории вещей не очень практично. Вместо этого упор делается на совершенствовании процесса разработки. В процесс включаются практики, приносящие наибольшую пользу и при этом вписывающиеся в бюджет (времени, денег, ресурсов). Конечная цель - выбор такой комбинации практик, которая обеспечивает приемлемый уровень риска. Например, комбинация 80% кода тестами, обязательный просмотр кода и интеграционное тестирование, привязанное к каждому выпуску софта может обеспечить лучший результат, чем просто 100% покрытие кода тестами при тех же затратах времени на разработку.
Остальные рекомендации этого исследования следуют этой же логике:
- Разработчики должны быть вовлечены в проектные решения, определяющие роль программного обеспечения в проекте, с самых ранних стадий разработки (иначе ошибочные решения потом вылезут боком).
- Симуляторы и тестовое железо должны быть доступны как можно ранее (иначе на тестирование софта не останется достаточно времени).
- Программная архитектура должна быть разработана до начала кодирования (иначе потом переделывать придется несколько раз).
- Референсная архитектура, включающая аппаратную и программную части, должна быть разработана заранее (чтобы проработать взаимодействие железа и софта).
- Используйте объективные метрики для мониторинга процесса разработки и оценки адекватности способов проверки софта (иначе откуда вы знаете, что движетесь в правильном направлении?).
Из хороших новостей, замечу, что согласно исследованию NASA за 2001 год:
Исключительно хороший процесс разработки может снизить количество ошибок до уровня около одной ошибки на 10000 строк кода.
Сравните с типичной оценкой в 1-10 ошибок на 1000 строк в коде коммерческих приложений.