Ведение дополнительных веток проекта отнюдь не бесплатно
Jan 20, 2008 · CommentsПрограммирование
Структура репозитория исходников типичного проекта обычно представляет собой дерево:
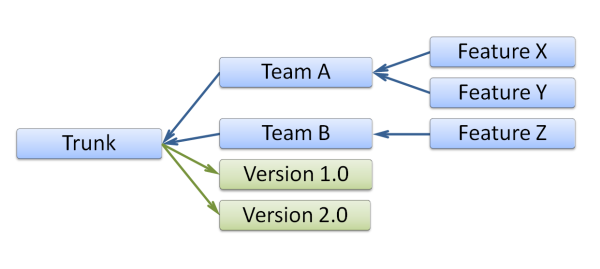
Основная ветка, от которой отходят ветки подразделений, команд и отдельных подпроектов. Новый код или исправления старого производятся в самых нижних ветках. Затем накопленные изменения перебрасываются в ветку, находящуюся выше по иерархии. При этом код проходит различные проверки, начиная от банальной «проверки временем», до прогона через формальный набор тестов различной сложности. Сложность и скрупулёзность проверок, как правило, растет при приближении к основной ветке. По мере надобности, от основной ветки отпочковываются ветки выпускаемых версий. Именно в них вносятся последние исправления и собирается финальная сборка продукта.
Такая схема имеет много преимуществ. Она позволяет эффективно изолировать разные команды друг от друга: изменения, сделанные одной командой, не мешают работе других. Легко контролировать перемещение кода из ветки в ветку. Код, по мере приближения к корню, проверяется всё тщательнее. Упрощается выпуск очередной версии и заплаток к уже выпущенным версиям.
Как обычно в любой бочке мёда есть своя ложка (а то и несколько) дёгтя. Одна из ложек данном случае, - чрезмерное увлечение созданием отдельных веток даже для самых маленьких фрагментов кода. Это мотивируется двумя аргументами: во-первых, создание все новых веток практически бесплатно с точки зрения необходимых ресурсов (процессорного времени и места на дисках), а во-вторых, инкапсуляция изменений в отдельной ветке повышает общую стабильность кода. Оба утверждения можно во многих случаях считать чистой воды заблуждениями.
Возьмем первое утверждение. С ним, в общем-то, все в порядке, до тех пор, пока размер проекта не вырастает в объеме во много раз. Для больших проектов становится важным и общий объем исходный файлов и время сборки продукта. В случае Windows, например, переключение между разными ветками может занимать больше часа, полная сборка системы и прогон базовых тестов - больше десятка часов даже на очень мощной машине. Кроме того, нужно собирать не одну версию системы, а шесть: отладочную и оптимизированную сборку для x86, amd64 и ia64. Учитывая, что в рабочем дне есть только 8 часов, то приходится либо ждать, либо планировать свои действия заранее. В принципе, это справедливо и не для таких монстров, как Windows. Можно сказать, что это применимо ко всем проектам, время сборки которых превышает полчаса-час.
Второе утверждение еще более спорно, чем первое. Дело в том, что создание отдельной ветки ничего не даёт само по себе. Стабильность кода обеспечивается качеством тестирования, через которое проходит код, перед своей интеграцией в родительскую ветку. В случае веток, расположенных ближе к основной ветке это и автоматическая ежедневная сборка, и автоматические тесты, плюс возможное ручное тестирование и т.д. В случае ветки, которой пользуется отдельный разработчик, ничего этого, как правило, нет. Вернее все должно делаться вручную. Опять же, если мы говорим о большом проекте, то у отдельного разработчика может просто не быть ресурсов для полноценного тестирования. В особо запущенных случаях и с ежедневной сборкой возникают проблемы.
Собственно вывод отсюда такой. Создание ветки в проекте автоматически подразумевает траты из бюджета на сервера (или процессорное время) для сборки и тестирования еще одного или нескольких версий продукта. Иначе ветка становится просто местом, где временно складываются непроверенные изменения.