Парсер C кода
Aug 16, 2007 · CommentsПрограммированиеWin32.Utf8
Поиск парсера для C кода – по-прежнему увлекательное занятие. Для Win32.Utf8 мне нужен был парсер для анализа заголовочных файлов Win32 API и извлечения из них прототипов функций и объявлений структур. Требований к нему было не очень много:
-
Разбор заголовка размером 2-3MB (размер windows.h после препроцессора) должен занимать разумное время – 20-30 секунд на типичной машине. В моем случае в качестве эталона выступает Athlon XP 1.5GHz;
-
Требовалось умение работать с нестандартными расширениями C - __declspec и прочим;
-
Парсер должен извлекать SAL описания параметров функций и членов структур;
-
Результат разбора должен быть удобен для последующего анализа;
Очевидный вариант – адаптировать парсер из GCC был отброшен сразу. Это не совсем тривиально, да и адаптировать его под себя не просто. Другой интересный вариант – использовать GCC-XML был также отвергнут из-за несовместимости с пунктами 2 и 3. Вывод напрашивался один – придётся писать собственный парсер.
Встала другая проблема какой парсер генератор использовать. Поскольку в качестве основного языка для проекты был выбран Python, то и рассматривались варианты генерирующие код на Python (или позволяющие писать код правил на Python). В финал вышли три претендента: PLY, SPARK и DParser.
PLY – полный аналог пары Lex и Yacc. PLY устраивал почти всем, кроме того факта, что он базируется на алгоритме LALR. Грамматика языка C не однозначна с точки зрения LALR и поэтому без специальных ухищрений парсить C код с помощью Yacc не получается.
C С++ в этом плане вообще беда. Его грамматика ещё более неоднозначна и с LR/LALR алгоритмами совсем не уживается.
В отличие от PLY, SPARK использует алгоритм Earley и может справиться с неоднозначной грамматикой без особых проблем. Подвох, однако, заключается в том, что сложность этого алгоритма – O(_n_3). Отзывы о SPARK это только подтверждали – медленный.
Несмотря на это я решил попробовать. Проведённый эксперимент показал, что SPARK вовсе даже и не медленный. Он ОЧЕНЬ И ОЧЕНЬ медленный. И к тому же охочий до памяти.
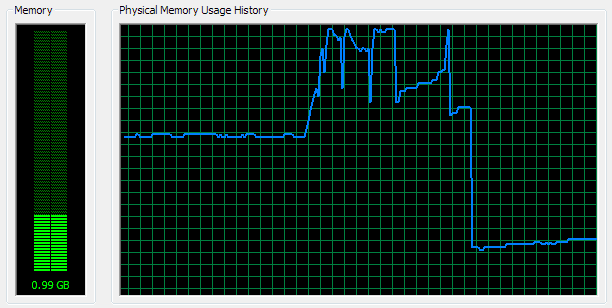
При попытке разобрать заголовок размером 2.5MB SPARK почти сразу израсходовал свободные 1.5GB памяти. Через несколько секунд, поняв, что так просто от назойливого приложения не отделаться, система сбросила в swap всё что могла. Освободившиеся два гигабайта были сожраны без промедления, после чего система впала в депрессию. Положение спасла ошибка в грамматике. Парсер поперхнулся на незнакомом слове «extern» и вывалился.
Интересно также, что на стареньком Althon XP график использования памяти рисовал симпатичную логарифмическую кривую. :-)
DParser тоже использует O(_n_3) алгоритм - GLR (Generalized LR), что не предвещало ничего хорошего. Впрочем GLR может быть значительно быстрее Earley в случае «почти детерминированной грамматики», включая грамматику C. К сожалению DParser не совсем тривиально подключается к Python под Windows. Так что и DParser пришлось исключить.
Осталась проблема как совместить неоднозначную грамматику C и PLY. Корень проблемы заключается в ключевом слове «typedef», вернее способности C объявлять новые типы с его помощью. Конструкции вроде:
typedef int foo;
foo;
foo x;
volatile foo;
int foo;
могут означать совсем разные вещи в зависимости от того, встретилась ли перед ними строчка «typedef bar foo;» или нет. Традиционно, эта проблема решается глобальным списком типов, пополняемого парсером. В процессе разбора лексер обращается к этому списку для разрешения неоднозначности: «является ли этот идентификатор именем типа или нет». Крайне полезная ссылка по этой теме (особенно последний пост): http://groups.google.com/group/comp.compilers/browse_thread/thread/82a790cb7997aa70/c0797b5b668605b4.