Использование Indexing Service для поиска по исходникам
Nov 6, 2006 · CommentsИнструменты
Я давно заметил одну странную вещь - разработчики не очень часто пользуются средствами быстрого поиска по исходникам. Это тем более странно, если учесть тот факт, что существует море доступных инструментов, в том числе множество Open Source проектов, посвященных индексированию и поиску. Я подозреваю, что это связано с отсутствием удобного пользовательского интерфейса. Просматривать исходники в браузере - что может быть хуже? Думаю, что если бы в Visual Studio была бы галочка “Индексировать исходные файлы”, которая автоматически включала индексацию, то 9 из 10 разработчиков использовали бы эту функциональность.
Самое интересное, что, начиная ещё с Windows 2000, средства полнотекстового поиска поставляются вместе с операционной системой. Я имею в виду Indexing Service. Для того чтобы построить на его основе полноценное средство поиска нужно совсем немного: фильтр для индексирования исходников и сколько-нибудь удобный в использовании поисковый клиент. Специализированный фильтр полезен потому, что в отличие от базового текстового фильтра, он умеет парсить код, извлекая дополнительную информацию, например объявления структур и функций. Тем самым пользователь получает возможность искать объявление функции или класса вместо всех упоминаний имени искомой функции или класса в проекте.
Фильтр для С++ (С++ IFilter) и подходящий GUI клиент (Srch) входят в состав VC++ PowerToys from GotDotNet. Собственно говоря, именно эту комбинацию (Indexing Service, C++ IFilter и Srch) я использую в повседневной работе, так что можно сказать, что эта информация из первых рук.
Вся установка и настройка заключается в регистрации фильтра (cxxfilt.dll) с помощью regsvr32.exe и создании Indexing Service каталога в Computer Management:
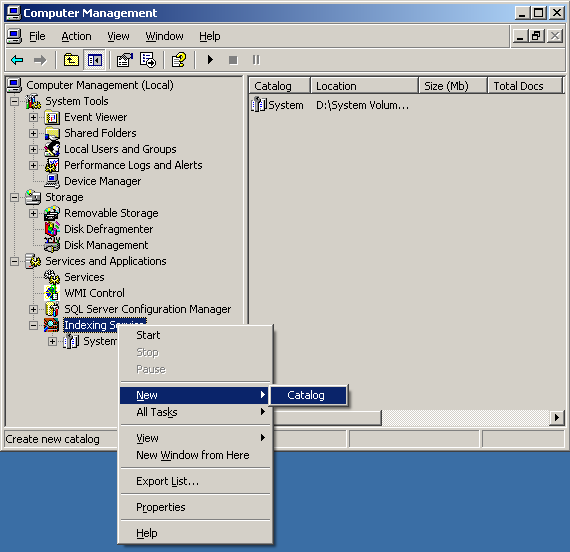
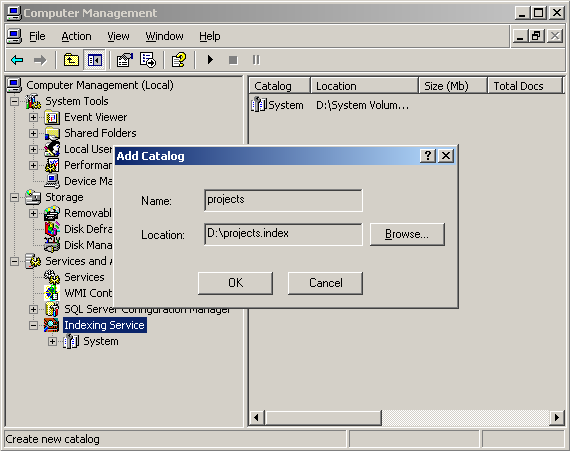
В каталог добавляются все индексируемые директории:
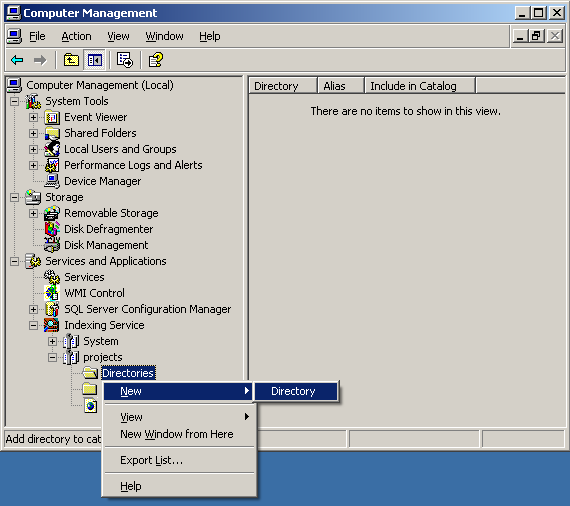
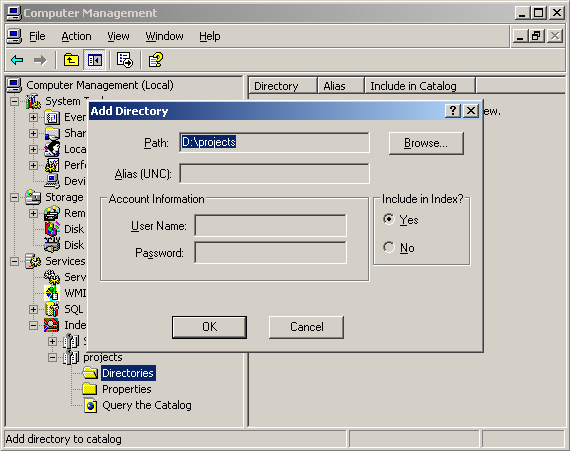
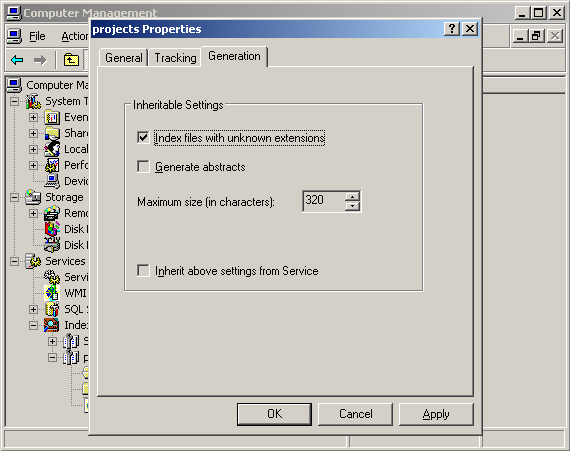
Также имеет смысл разрешить индексирование файлов с неизвестными расширениями в свойствах каталога. Иначе файлы вроде “makefile” не будут проиндексированы:
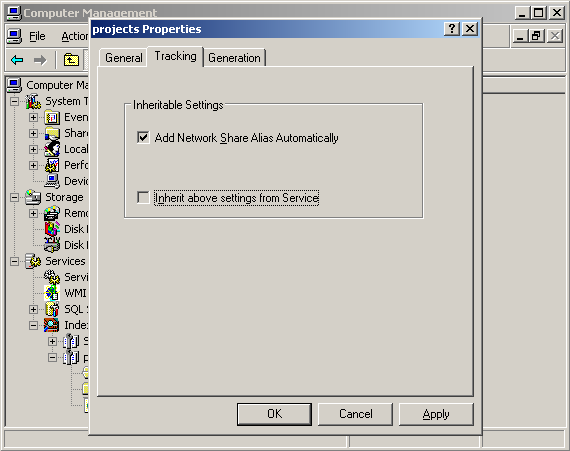
Indexing Service также позволяет автоматически настраивать удаленный доступ к проиндексированным файлам, что очень удобно в случае, когда для индексирования используется выделенный компьютер:
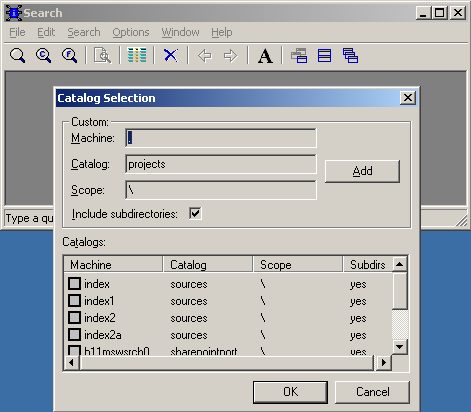
После того, как Indexing Service проиндексирует все файлы можно попробовать поискать что-нибудь. Итак, запускаем Srch, выбираем нужный каталог:
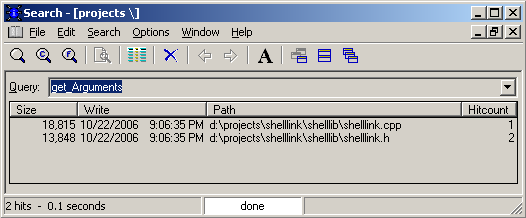
… и ищем, скажем, “get_Arguments”:
Интерфейс этой утилиты довольно таки спартанский, однако, вполне функциональный. Двойной щелчок в списке найденных файлов открывает окно с исходным кодом:
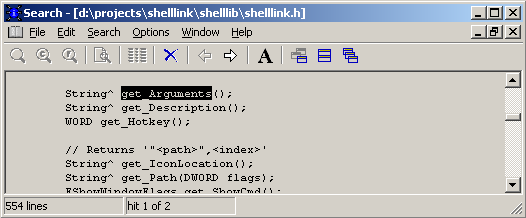
Кнопки “Previous” и “Next” перемещают фокус между найденными словами. Ctrl+Tab и Ctrl+Shift+Tab переключают фокус между окнами.
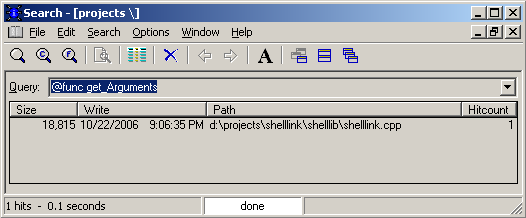
Утилита поддерживает развитый язык запросов. Его краткое описание можно найти в “справочной системе” утилиты (если, конечно, так можно назвать .chm файл из трех страниц. :-) Например, запрос “@func get_Argument” найдёт только файлы, содержащие определение функции get_Argument:
Вот и всё на сегодня.